|
I am an Associate Professor at the School of Computer Science, Huazhong University of Science and Technology, where I co-lead the HUST Media Lab. My research interests primarily lie in the areas of imaging, graphics, computer vision, and artificial intelligence. Before joining HUST, I worked in the Advanced Technology and Projects (ATAP) division at Google in Mountain View, USA. As a proud member of the Te'veren team, I collaborated with Rick Marks on advanced sensing and on-device intelligence using computer vision. Prior to Google, I served as a Principal Scientist at DGene, US, where I conducted research on real-time volumetric human capture systems. I graduated from the University of Delaware in 2017, where I majored in Computer Science. At UDel, I worked with Professor Jingyi Yu on research problems in computational photography and scene understanding. During my PhD, I interned at Adobe, hosted by the ACR team, in 2015. I am actively seeking creative and highly motivated MS and PhD students who are passionate about research. |
|
|
|
† denotes corresponding author |

|
Kaixin Yao, Longwen Zhang, Xinhao Yan, Yan Zeng, Qixuan Zhang, Wei Yang, Lan Xu†, Jiayuan Gu†, Jingyi Yu† SIGGRAPH, 2025 (Best Paper Award) Project / Paper We propose CAST, a novel method for component-aligned 3D scene recovery. CAST segments objects and estimating relative depth from the input image, inferring inter-object relations, generating occlusion-robust object geometry using point-cloud conditioning, aligning meshes via generative transformations, and enforcing physical plausibility with a relation-derived constraint graph. |

|
Longwen Zhang, Qixuan Zhang, Haoran Jiang, Yinuo Bai, Wei Yang, Lan Xu†, Jingyi Yu† SIGGRAPH, 2025 Project / Paper / arxiv We introduces BANG, a novel generative approach that bridges 3D generation and reasoning, allowing for intuitive and flexible part-level decomposition of 3D objects. At the heart of BANG is "Generative Exploded Dynamics", which creates a smooth sequence of exploded states for an input geometry, progressively separating parts while preserving their geometric and semantic coherence. |

|
Youjia Zhang, Anpei Chen†, Yumin Wan, Zikai Song, Junqing Yu, Yawei Luo Wei Yang† CVPR, 2025 Paper / Project Ref-GS builds upon the deferred rendering of Gaussian splatting and applies directional encoding to the deferred-rendered surface, effectively reducing the ambiguity between orientation and viewing angle. We introduce a spherical Mip-grid to capture varying levels of surface roughness, enabling roughness-aware Gaussian shading. |
|
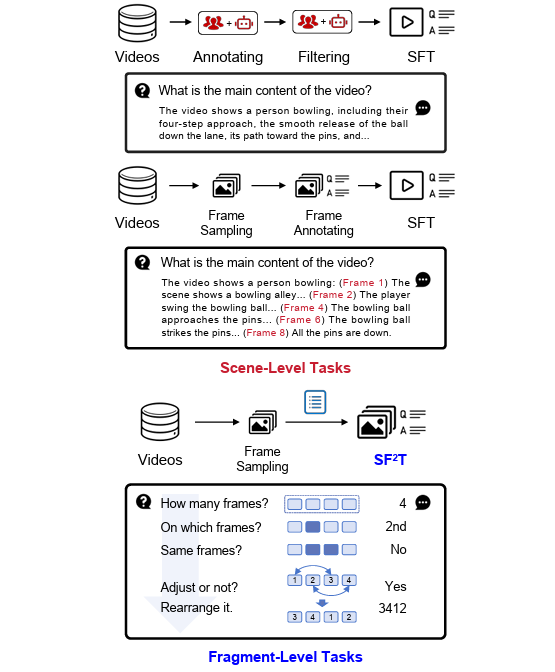
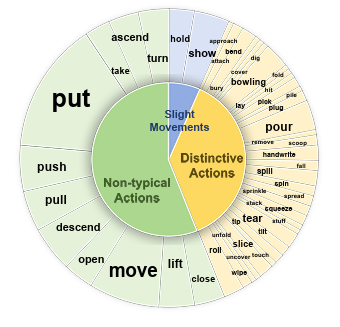
Yangliu Hu, Zikai Song†, Na Feng, Yawei Luo Junqing Yu Yi-Ping Phoebe Chen, Wei Yang† CVPR, 2025 Paper / Project We propose the Self-Supervised Fragment Fine-Tuning (SF^2T), a novel effortless fine-tuning method, employs the rich inherent characteristics of videos for training, while unlocking more fine-grained understanding ability of Video-LLMs, along with a novel benchmark dataset, namely FineVidBench, for rigorously assessing Video-LLMs' performance at both the scene and fragment levels, offering a comprehensive evaluation of their capabilities. |
|
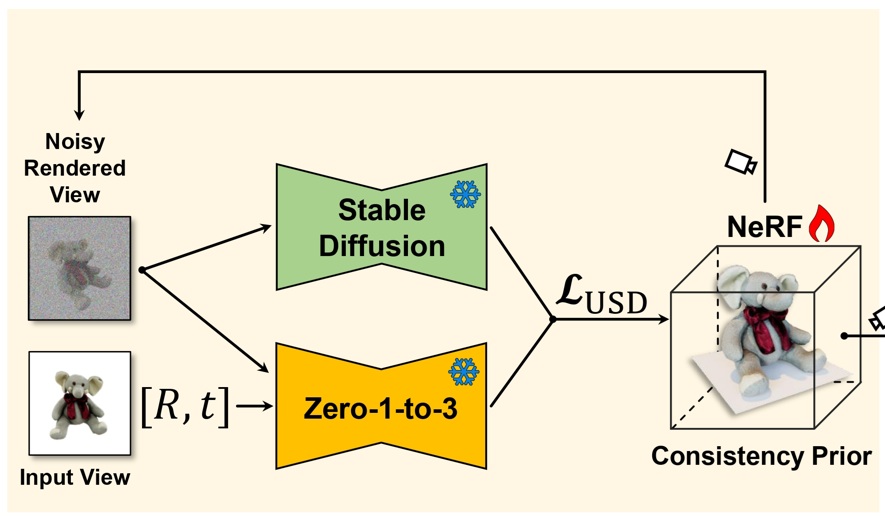
Youjia Zhang, Zikai Song, Junqing Yu, Yawei Luo Wei Yang† IJCAI, 2025 Paper / Project / Code We propose the USD, which achieves consistent single-to-multi-view synthesis and geometry recovery by using a radiance-field consistency prior and Unbiased Score Distillation—injecting unconditioned 2D diffusion noise to debias optimization—followed by a two-step, object-aware denoising process that yields high-quality views for accurate geometry and texture. |

|
Longwen Zhang, Ziyu Wang, Qixuan Zhang, Qiwei Qiu, Anqi Pang, Haoran Jiang Wei Yang, Lan Xu†, Jingyi Yu† SIGGRAPH, 2024 (Honorable Mentions) Project / Paper / Website We introduce CLAY, a 3D geometry and material generator designed to effortlessly transform human imagination into intricate 3D digital structures. CLAY supports classic text or image inputs as well as 3D-aware controls from diverse primitives (multi-view images, voxels, bounding boxes, point clouds, implicit representations, etc). |
|
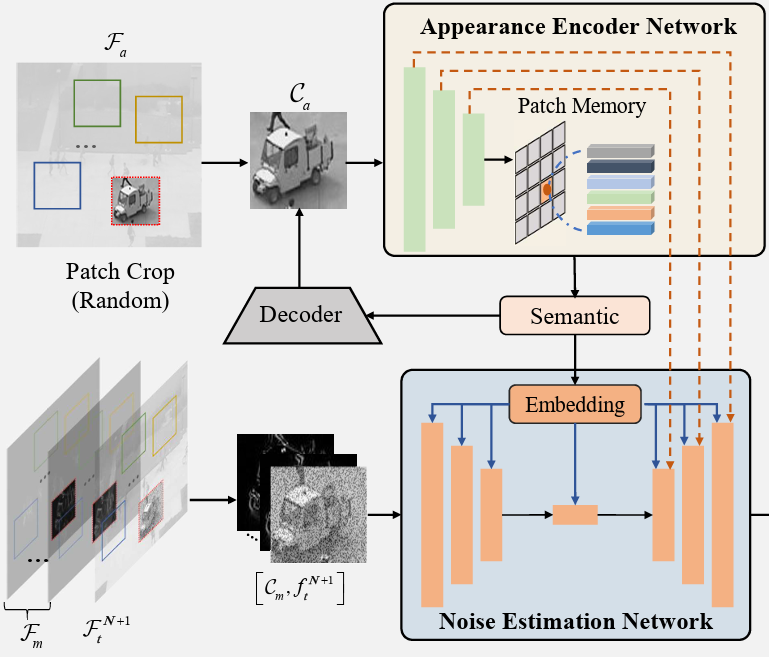
Hang Zhou, Jiale Cai, Yuteng Ye, Yonghui Feng, Chenxing Gao, Junqing Yu, Zikai Song†, Wei Yang ACM MM, 2024 Paper We introduce innovative motion and appearance conditions that are seamlessly integrated into a patch diffusion model to guide the model in generating coherent and contextually appropriate predictions for both semantic content and motion relations. |

|
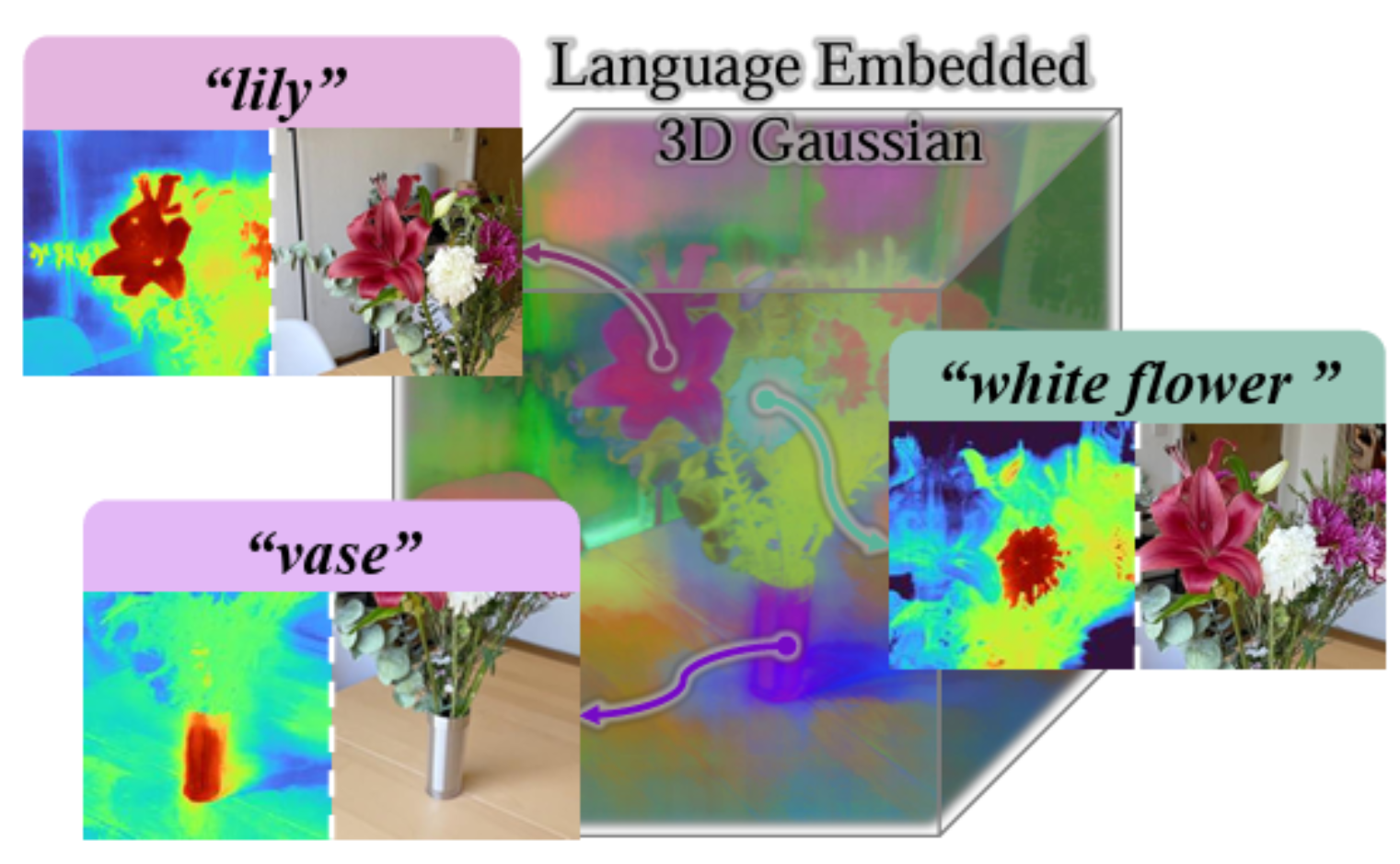
Zikai Song, Ying Tang, Run Luo, Lintao Ma, Junqing Yu†, Yi-Ping Phoebe Chen, Wei Yang† ACM MM, 2024 Paper / Project ALTrack is a coherent point tracking framework which designes an autogenic language embedding for visual feature enhancement, strengthens point correspondence in long-term sequences. Unlike existing visual-language schemes, our approach learns text embeddings from visual features through a dedicated mapping network, enabling seamless adaptation to various tracking tasks without explicit text annotations. |
|
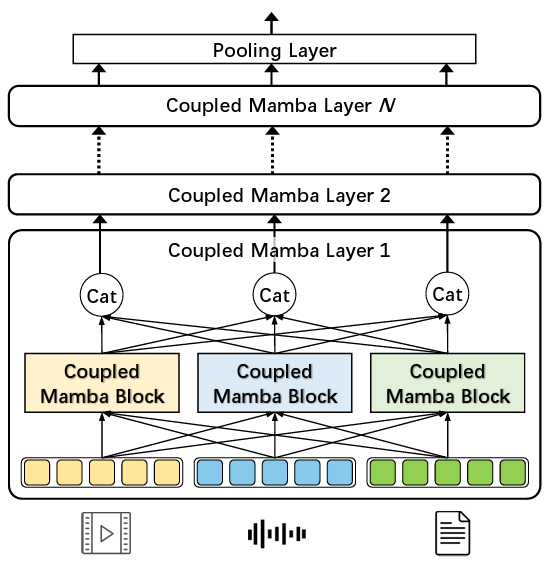
Wenbing Li, Hang Zhou, Junqing Yu Zikai Song†, Wei Yang† NeurIPS, 2024 Paper / Code We propose the Coupled SSM model, which links the state chains of multiple modalities while keeping intra-modality processes independent. Our model includes an inter-modal state transition mechanism, where the current state depends on both its own chain and neighboring chains' states from the previous time step. |
|
Teng Xu, Jiamin Chen, Peng Chen, Youjia Zhang, Junqing Yu, Wei Yang† ArXiv, 2024 Project / Paper We propose a Coherent Score Distillation (CSD) that aggregates a 2D image editing diffusion model and a multi-view diffusion model for score distillation, producing multi-view consistent editing with much finer details. |
|
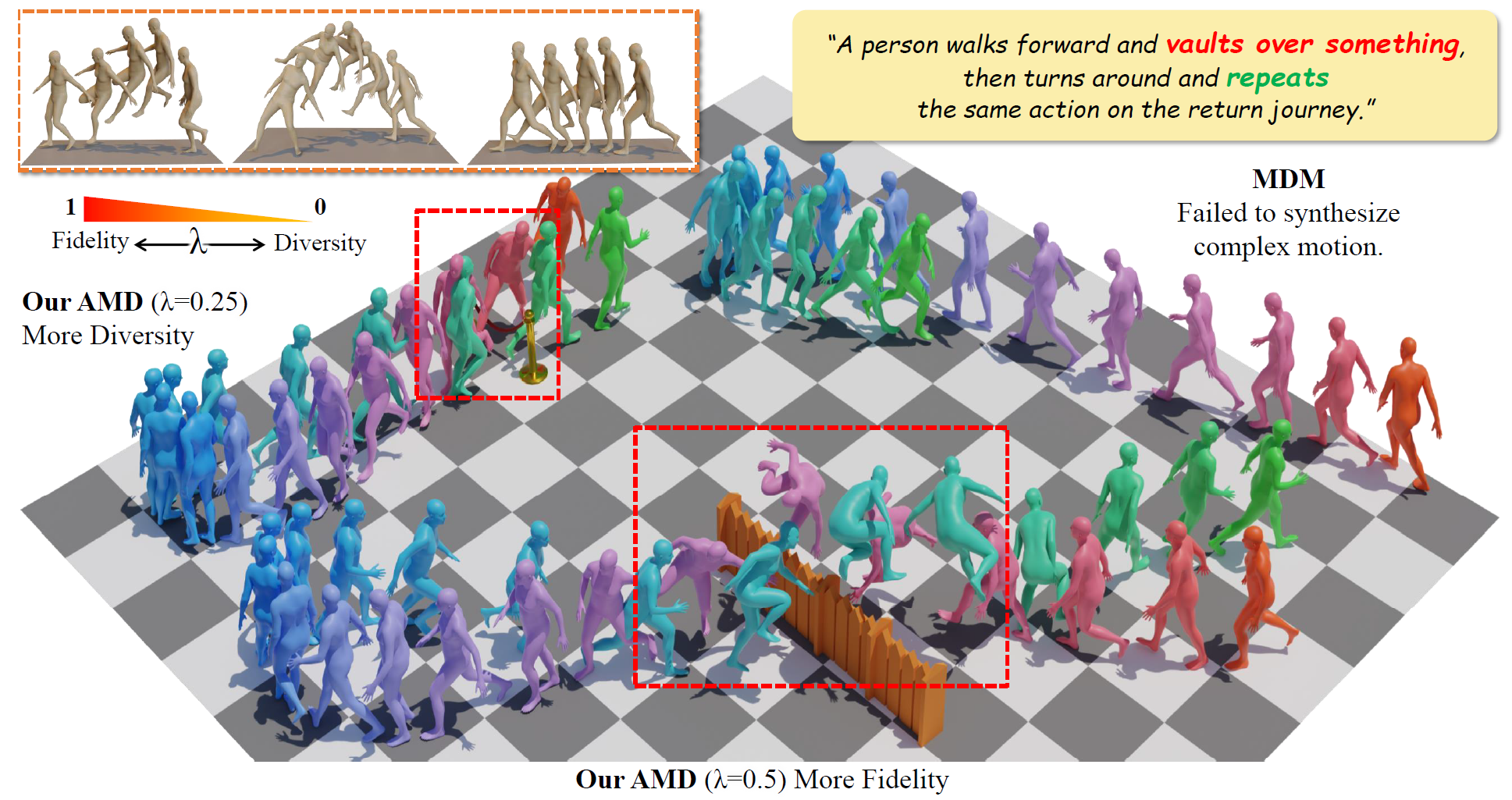
Beibei Jing, Youjia Zhang, Zikai Song, Junqing Yu, Wei Yang† AAAI, 2024 Paper / Code Comming Soon We propose the Adaptable Motion Diffusion (AMD) model, which leverages a Large Language Model (LLM) to parse the input text into a sequence of concise and interpretable anatomical scripts that correspond to the target motion. |

|
Yuteng Ye, Jiale Cai, Hang Zhou, Guanwen Li, Youjia Zhang, Zikai Song, Chenxing Gao, Junqing Yu, Wei Yang† AAAI, 2024 Paper / Code We propose to harness the capabilities of a Large Language Model (LLM) to decompose text descriptions into coherent directives adhering to stringent formats and progressively generate the target image. |
|
Chenxing Gao, Hang Zhou, Junqing Yu, YuTeng Ye, Jiale Cai, Junle Wang, Wei Yang† AAAI, 2024 Paper Cooming Soon We present a label-free white-box attack approach for ViT-based models that exhibits strong transferability to various black-box models by accelerating the feature collapse. |
|
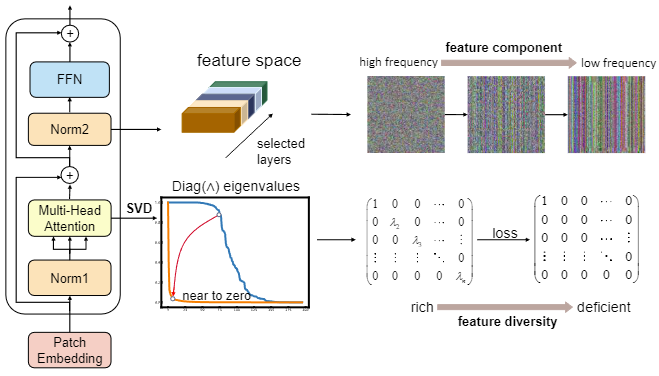
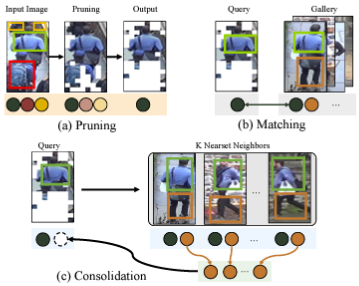
Yuteng Ye, Hang Zhou, Junqing Yu, Qiang Hu, Wei Yang† AAAI, 2024 Paper / Code We propose a Feature Pruning and Consolidation (FPC) framework to circumvent explicit human structure parse, which consists of a sparse encoder, a global and local feature ranking module, and a feature consolidation decoder. |
|
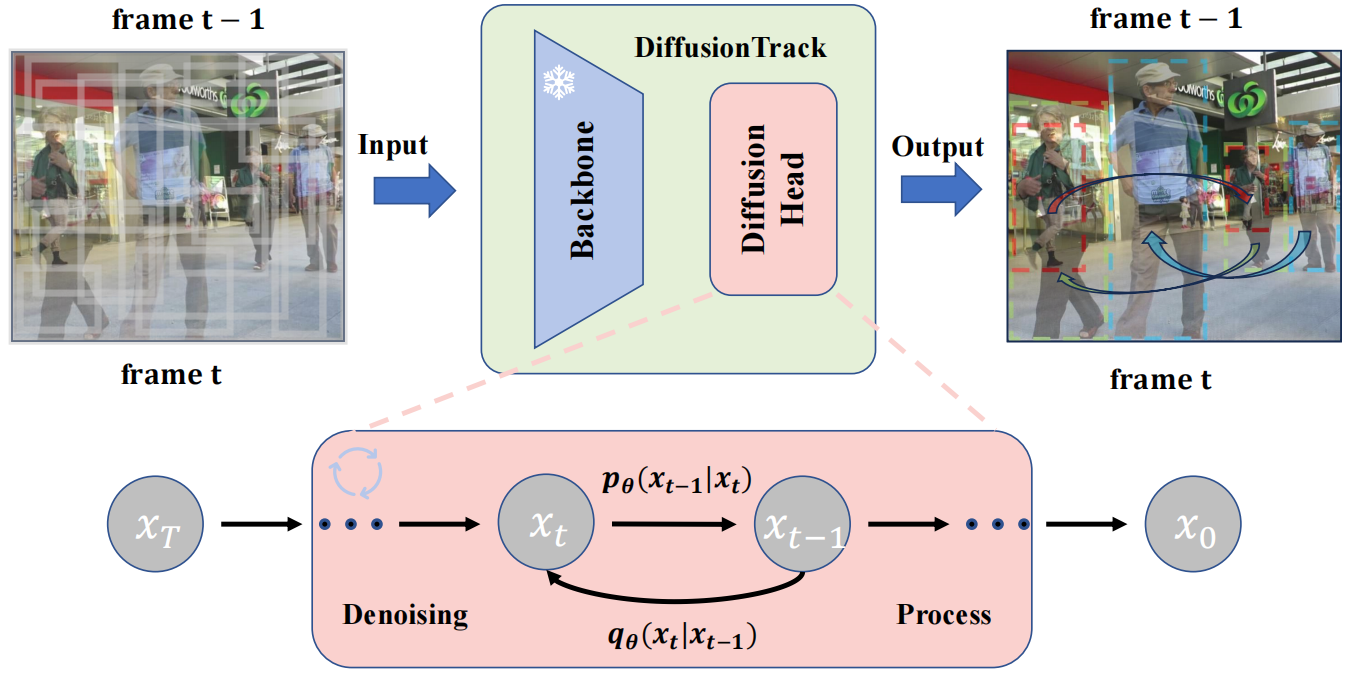
Run Luo, Zikai Song, Lintao Ma, Jinlin Wei, Wei Yang, Min Yang AAAI, 2024 Paper / Code We formulates object detection and association jointly as a consistent denoising diffusion process from paired noise boxes to paired ground-truth boxes. |
|
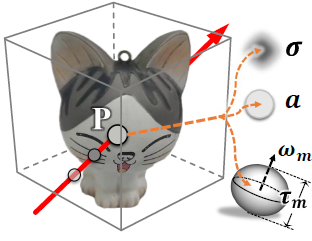
Youjia Zhang, Teng Xu, Junqing Yu, Yuteng Ye, Yanqing Jing, Junle Wang, Jingyi Yu Wei Yang† ICCV, 2023 arXiv / Project Page We propose to conduct inverse volume rendering by representing a scene using microflake volume, which assumes the space is filled with infinite small flakes and light reflects or scattersat each spatial location according to microflake distributions. |
|
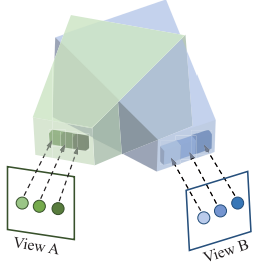
Luoyuan Xu, Tao Guan, Yuesong Wang, Wenkai Liu, Zhaojie Zeng, Junle Wang, Wei Yang ICCV, 2023 Paper We propose to construct per-view cost frustum and fuse cross-view frustums for finer geometry estimation. |

|
Longwen Zhang, Qiwei Qiu, Hongyang Lin, Qixuan Zhang, Cheng Shi, Wei Yang, Ye Shi, Sibei Yang, Lan Xu, Jingyi Yu SIGGRAPH, 2023 arXiv / Project Page / Video / Web Demo / Huggingface Space DreamFace is a progressive scheme to generate personalized 3D faces under text guidance. |

|
Longwen Zhang, Zijun Zhao, Xinzhou Cong, Qixuan Zhang, Shuqi Gu, Yuchong Gao, Rui Zheng, Wei Yang, Lan Xu, Jingyi Yu SIGGRAPH, 2023 arXiv / Project Page / Video We introduce HACK (Head-And-neCK), a novel parametric model for constructing the head and cervical region of digital humans. |
 
|
Yuesong Wang, Zhaojie Zeng, Tao Guan, Wei Yang, Zhuo Chen, Wenkai Liu, Luoyuan Xu, Yawei Luo CVPR, 2023 Paper / Code We transplant the spirit of deformable convolution into the PatchMatch-based method for both memory-friendly and textureless-resilient MVS. |
|
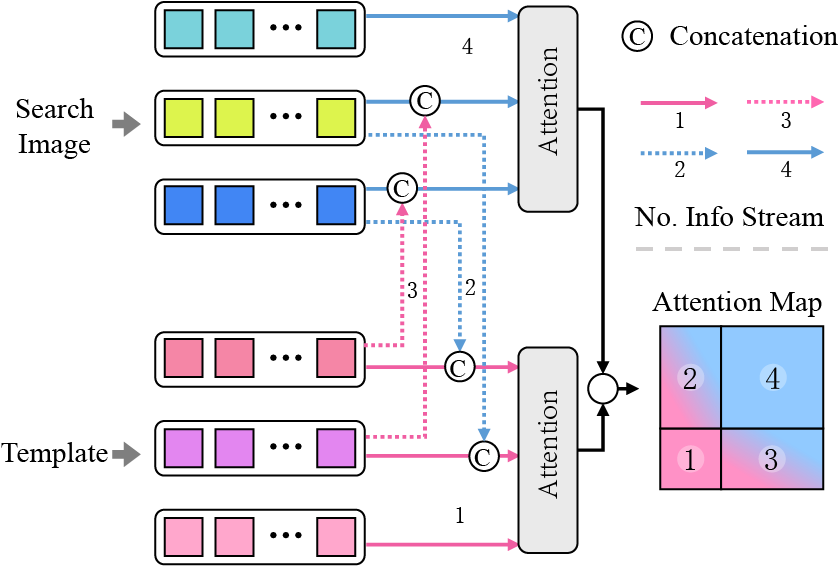
Zikai Song, Run Luo, Junqing Yu†, Yi-Ping Phoebe Chen, Wei Yang† AAAI, 2023 (Oral Presentation) arXiv / Code We demonstrate the basic vision transformer (ViT) architecture is sufficient for visual tracking with correlative masked modeling for information aggregation enhancement. |
|
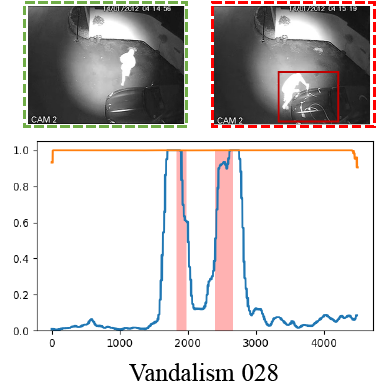
Hang Zhou, Junqing Yu†, Wei Yang† AAAI, 2023 (Oral Presentation) arXiv / Code We propose an Uncertainty Regulated Dual Memory Units (UR-DMU) model to learn both the representations of normal data and discriminative features of abnormal data. |

|
Fuqiang Zhao, Wei Yang, Jiakai Zhang, Pei Lin, Yingliang Zhang, Jingyi Yu, Lan Xu CVPR, 2022 Project Page / arXiv / Code / Video We present a neural representation with efficient generalization ability for high-fidelity free-view synthesis of dynamic humans. |
|
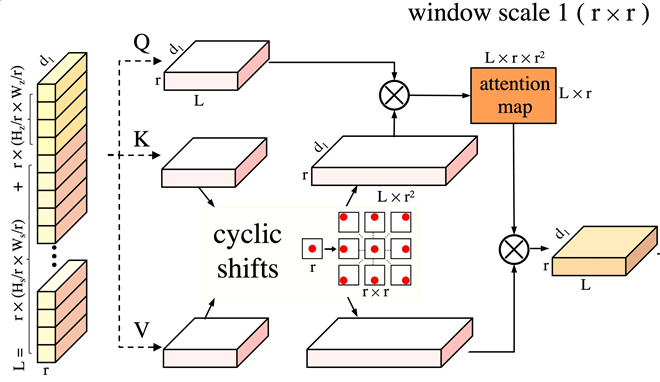
Zikai Song, Junqing Yu, Yi-Ping Phoebe Chen, Wei Yang CVPR, 2022 arXiv / Code CSWinTT is a new transformer architecture with multi-scale cyclic shifting window attention for visual object tracking, elevating the attention from pixel to window level. |

|
Haimin Luo, Teng Xu, Yuheng Jiang, Chenglin Zhou, Qiwei Qiu, Yingliang Zhang, Wei Yang, Lan Xu, Jingyi Yu SIGGRAPH, 2022 Project Page / arXiv / Code / Video ARTEMIS, the core of which is a neural-generated (NGI) animal engine, enables interactive motion control, real-time animation and photo-realistic rendering of furry animals. |
|
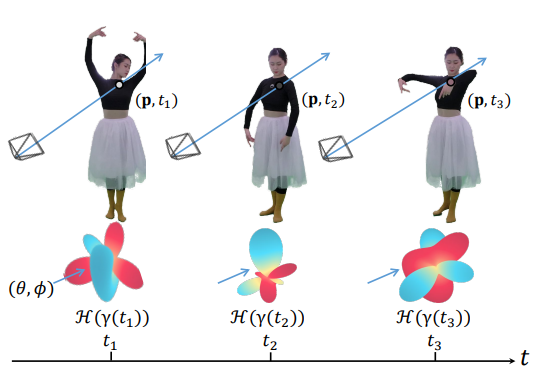
Jiakai Zhang, Liao Wang, Xinhang Liu, Fuqiang Zhao, Minzhang Li, Haizhao Dai, Boyuan Zhang, Wei Yang, Lan Xu, Jingyi Yu arXiv preprint, 2202.06088 arXiv NeuVV introduces a hyper-spherical harmonics (HH) decomposition for modeling smooth color variations over space and time. |
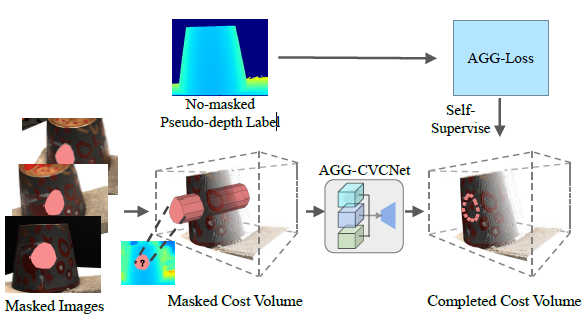
|
Luoyuan Xu, Tao Guan, Yuesong Wang, Yawei Luo Zhuo Chen, Wenkai Liu, Wei Yang ACM Multimedia, 2022 Paper We propose the AGG-CVCNet to learn complete geometry inference from partial observations with high confidence. |

|
Longwen Zhang, Chuxiao Zeng, Qixuan Zhang, Hongyang Lin, Ruixiang Cao, Wei Yang, Lan Xu, Jingyi Yu SIGGRAPH Asia, 2022 Project Page / arXiv / Video We present a learning-based, video-driven approach for generating dynamic facial geometries with high-quality physically-based assets |

|
Xin Chen, Anqi Pang, Wei Yang, Peihao Wang, Lan Xu, Jingyi Yu SIGGRAPH, 2022 (TOG) Project Page / arXiv / Code / Video TightCap is a data-driven scheme to capture both the human shape and dressed garments accurately with only a single 3D human scan. |
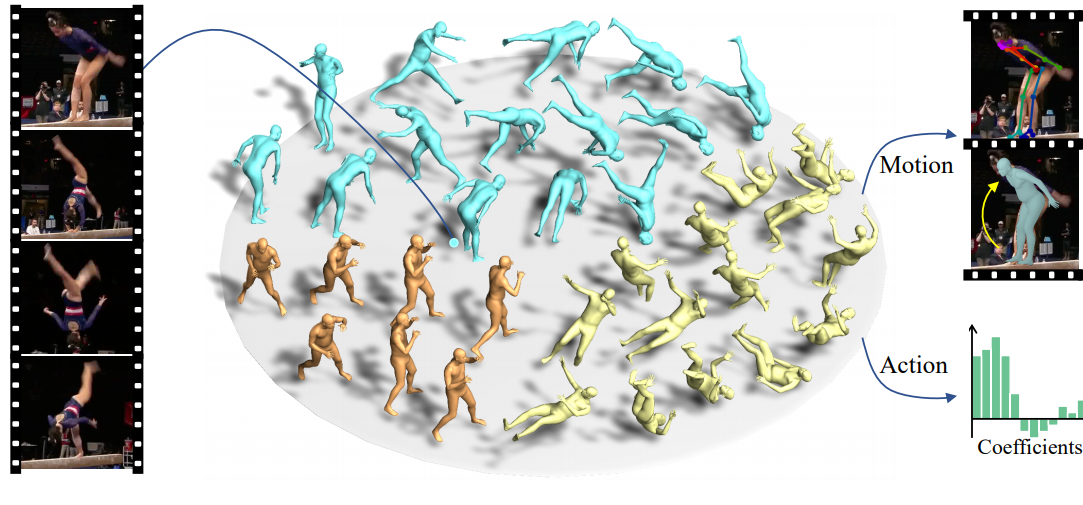
|
Xin Chen, Anqi Pang, Wei Yang, Yuexin Ma, Lan Xu, Jingyi Yu IJCV, 2022 (TOG) Project Page / arXiv / Code / Video SportsCap -- the first approach for simultaneously capturing 3D human motions and understanding fine-grained actions from monocular challenging sports video input |
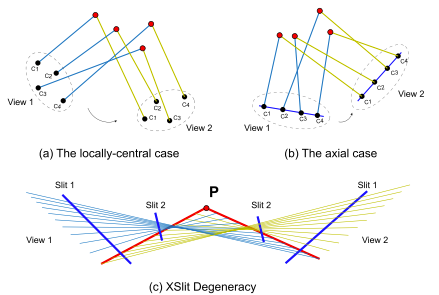
|
Wei Yang, Yingliang Zhang, Jinwei Ye, Yu Ji, Zhong Li, Mingyuan Zhou, Jingyi Yu TPAMI, 2019 Paper We present a structure-from-motion (SfM) framework based on a special type of multi-perspective camera called the cross-slit or XSlit camera. |
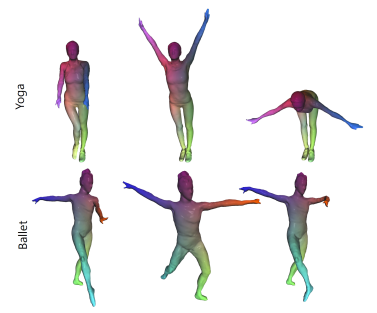
|
Zhong Li, Yu Ji, Wei Yang, Jinwei Ye, Jingyi Yu 3DV, 2017 (Spotlight Oral Presentation) arXiv / Video / Data We generate a global full-body template by registering all poses in the acquired motion sequence, and then construct a deformable graph by utilizing the rigid components in the global template. |

|
Yingliang Zhang, Zhong Li, Wei Yang, Peihong Yu, Haiting Lin, Jingyi Yu ICCP, 2017 Paper We use the light field (LF) camera such as Lytro and Raytrix as a virtual 3D scanner. |

|
Yingliang Zhang, Peihong Yu, Wei Yang, Yuanxi Ma, Jingyi Yu ICCV, 2017 Paper We present a comprehensive theory on ray geometry transforms under light field pose variations, and derive the transforms of three typical ray manifolds. |

|
Wei Yang, Haiting Lin, Sing Bing Kang, Jingyi Yu ICCV, 2015 Paper We present the depth dependent aspecratio (DDAR) property that can be used to 3D recovery. |

|
Wei Yang, Yu Ji, Haiting Lin, Yang Yang, Sing Bing Kang, Jingyi Yu CVPR, 2015 Paper We present a novel computational imaging solution for recovering AO by adopting a compressive sensing framework. |
|
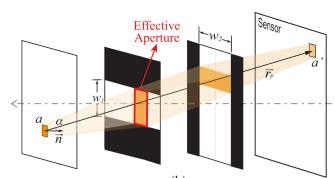
Jinwei Ye, Yu Ji, Wei Yang, Jingyi Yu ECCV, 2014 (Oral Presentation) Paper / Video We explore coded aperture solutions on a special non-centric lens called the crossedslit (XSlit) lens. |
|
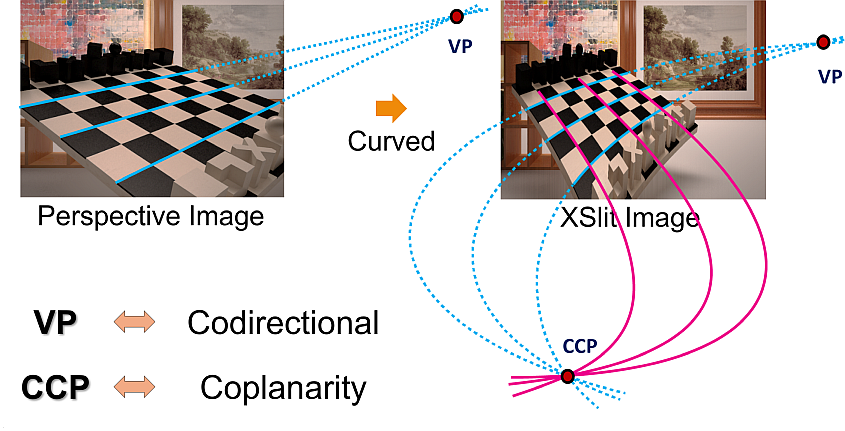
Wei Yang, Yu Ji, Jinwei Ye, S. Susan Young, Jingyi Yu ECCV, 2014 Paper We address the problem of determining CCP existence in general non-centric cameras. |
|
I borrowed this website template from Jon Barron, thanks! |